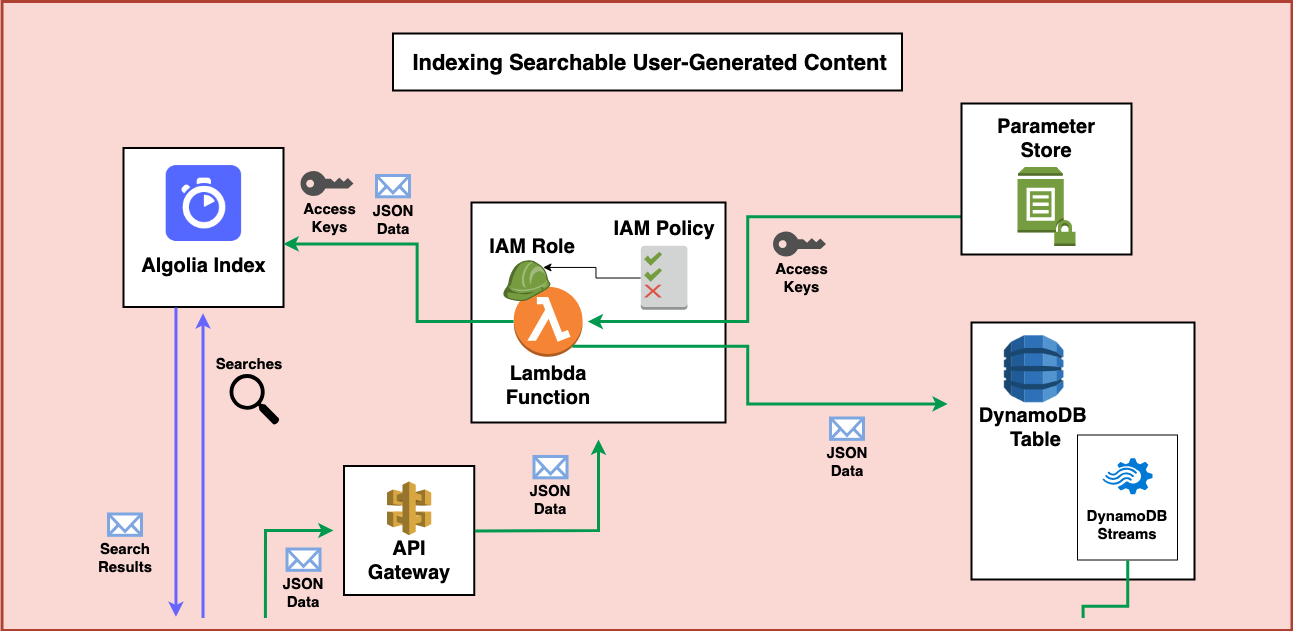
Searchable content is a common component of many modern applications. But for applications that rely on a streams of new user-generated content how can we create a system that reliably and rapidly indexes searchable content and also provides ways to update, and act on changes to that data later on? This post will show you an architecture that can accomplish this using AWS services like Lambda, API Gateway, S3, Systems Manager Parameter Store, and DynamoDB. We’ll also use the third party provider Algolia for search.
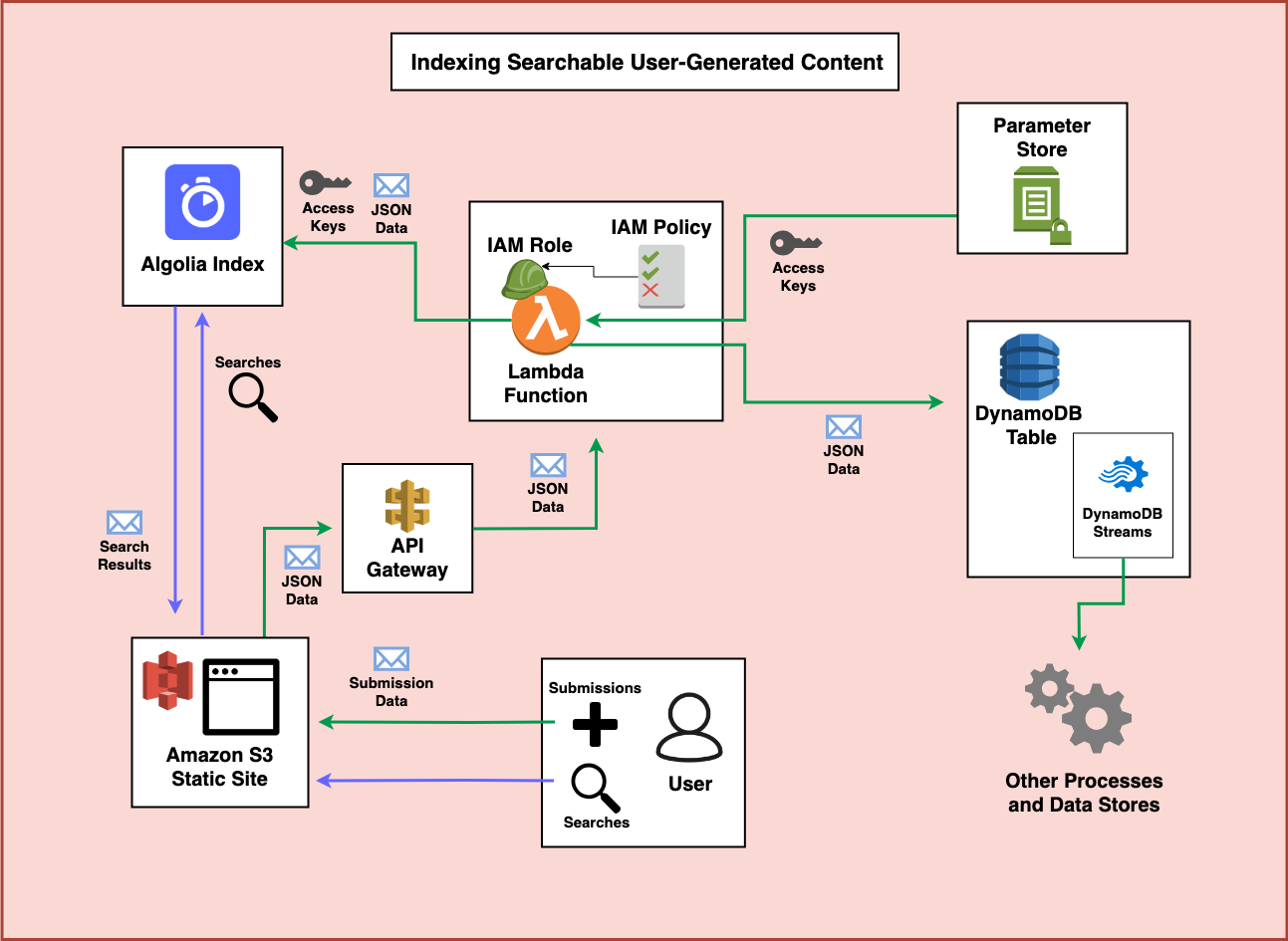
Our Full Architecture
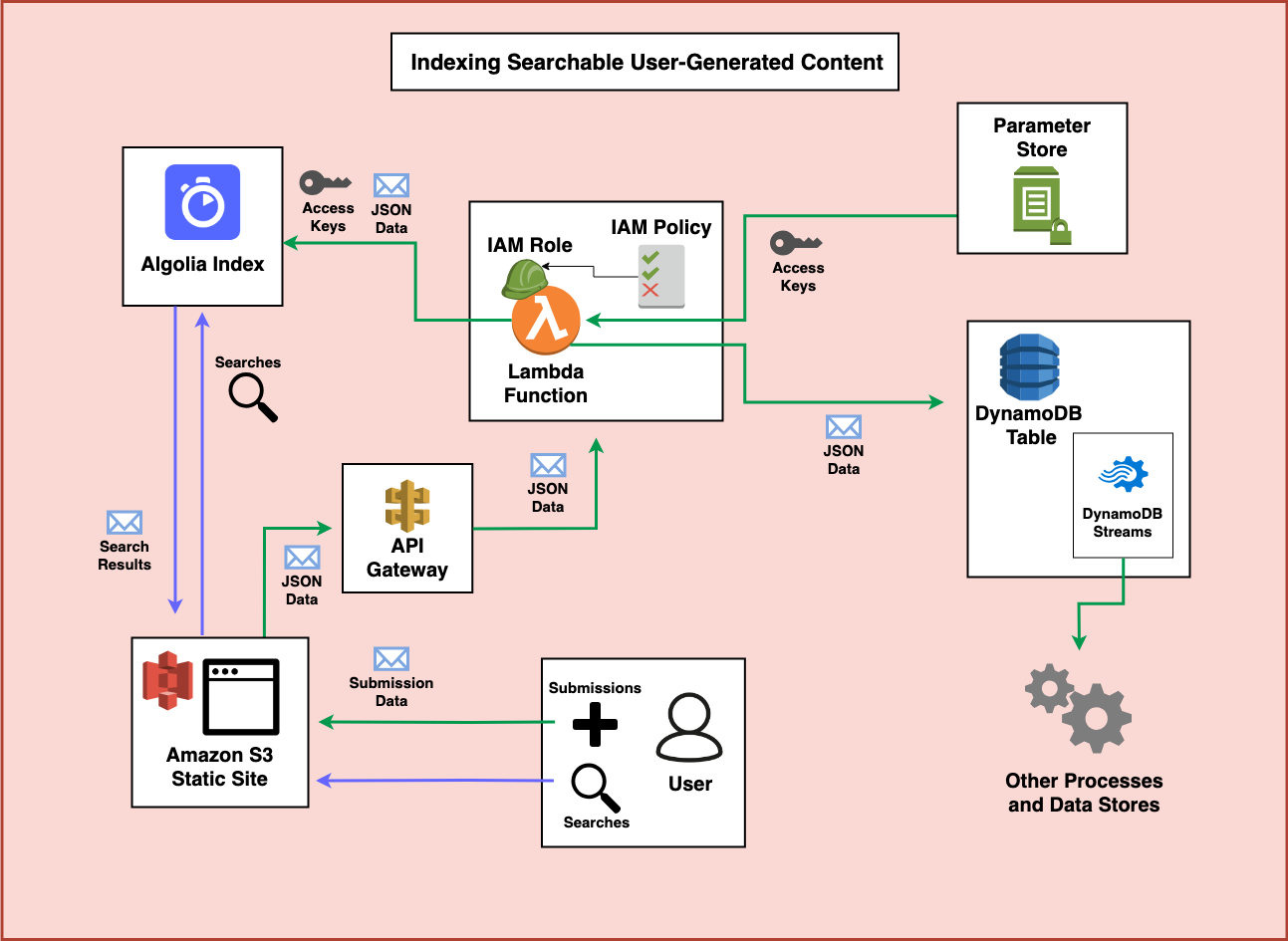
So let’s take a moment and walk through how we could make an application like this, step by step.
Step 1 - The Frontend
The very first part of this entire application is the frontend. In this case, I’m more interested in the backend of the application so I wont dive into much detail. But I think one excellent solution is to use the Serverless Website Component to deploy everything from a complex React application to a simple HTML/CSS/JavaScript website. After you register your domain with Amazon Route 53 you can use it to set up a CloudFront CDN, configure the S3 website hosting, create and associate an HTTPS certificate with your domain, and deploy your entire website in under ten lines of configuration. (Note: I’ve used the Serverless Framework for years now, but I recently started working at Serverless Inc. so I’m probably biased)
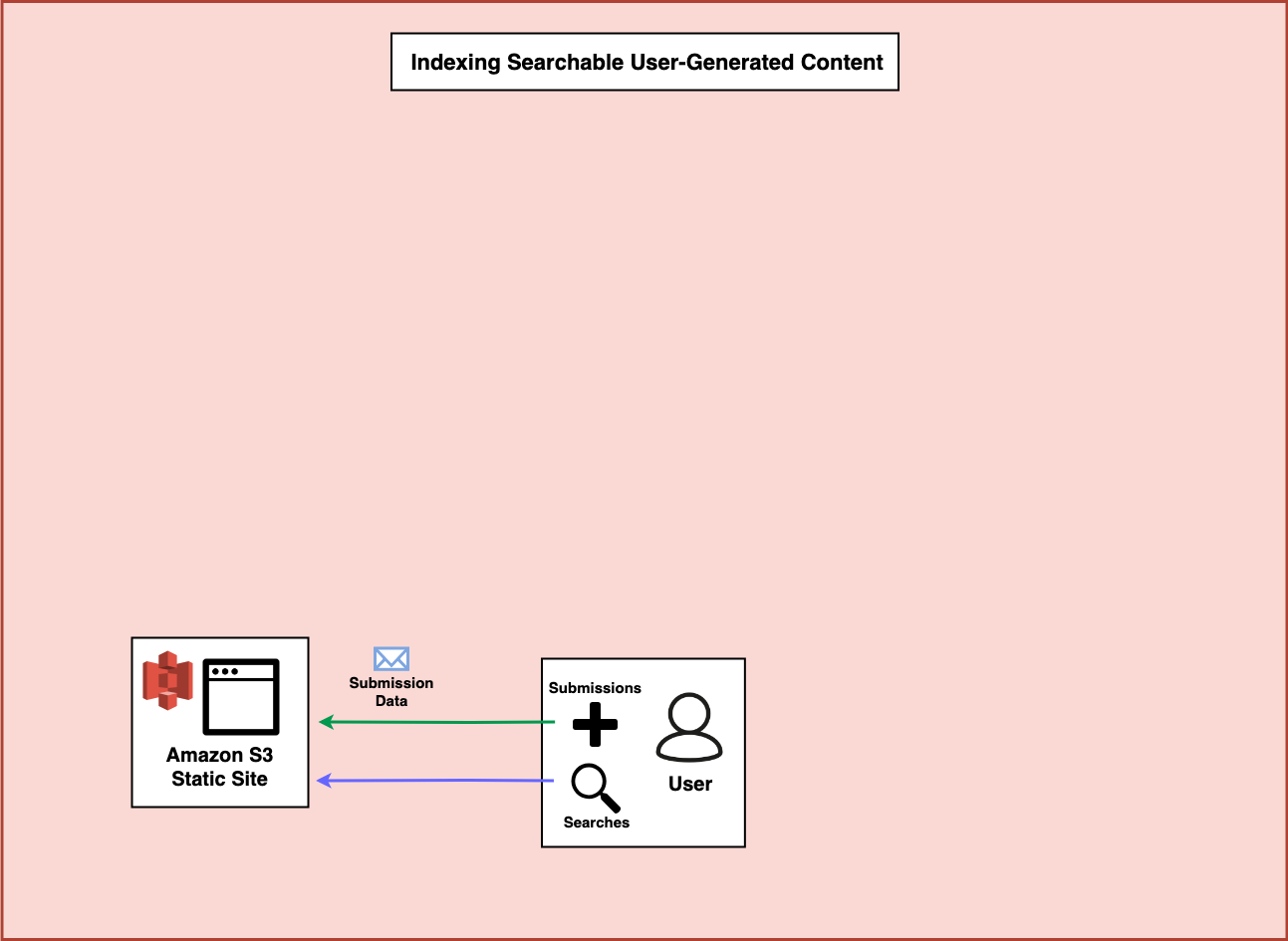
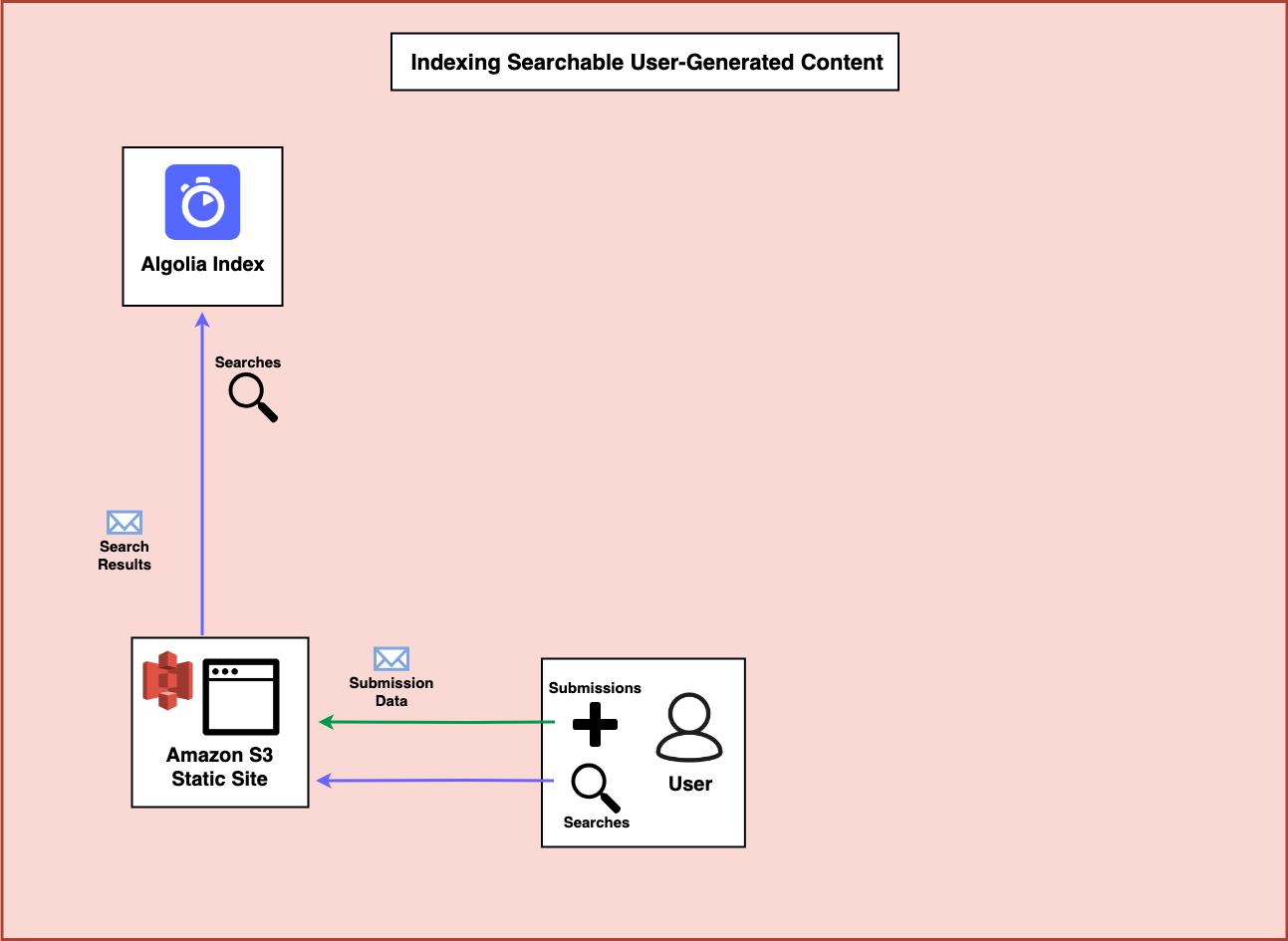
When the user visits your website, you’ll need a way to let users search Algolia for data that is already in your system and a way to allow users to submit data to your system.
Step 2 - Algolia Search
In order to enable an easy search UI, you can leverage the great tools Algolia has to help develop search UIs.
Step 3 - API Gateway
You’ll also need to set up an API endpoint that can accept POST data. An easy way to do this is to use the Serverless Framework and HTTP Events to trigger a Lambda Function. In a more sophisticated setup you can require authentication using something like Auth0 or Amazon Cognito. Alternatively, you could use Google reCAPTCHA to prevent spam and verify the requests after they are POSTed.
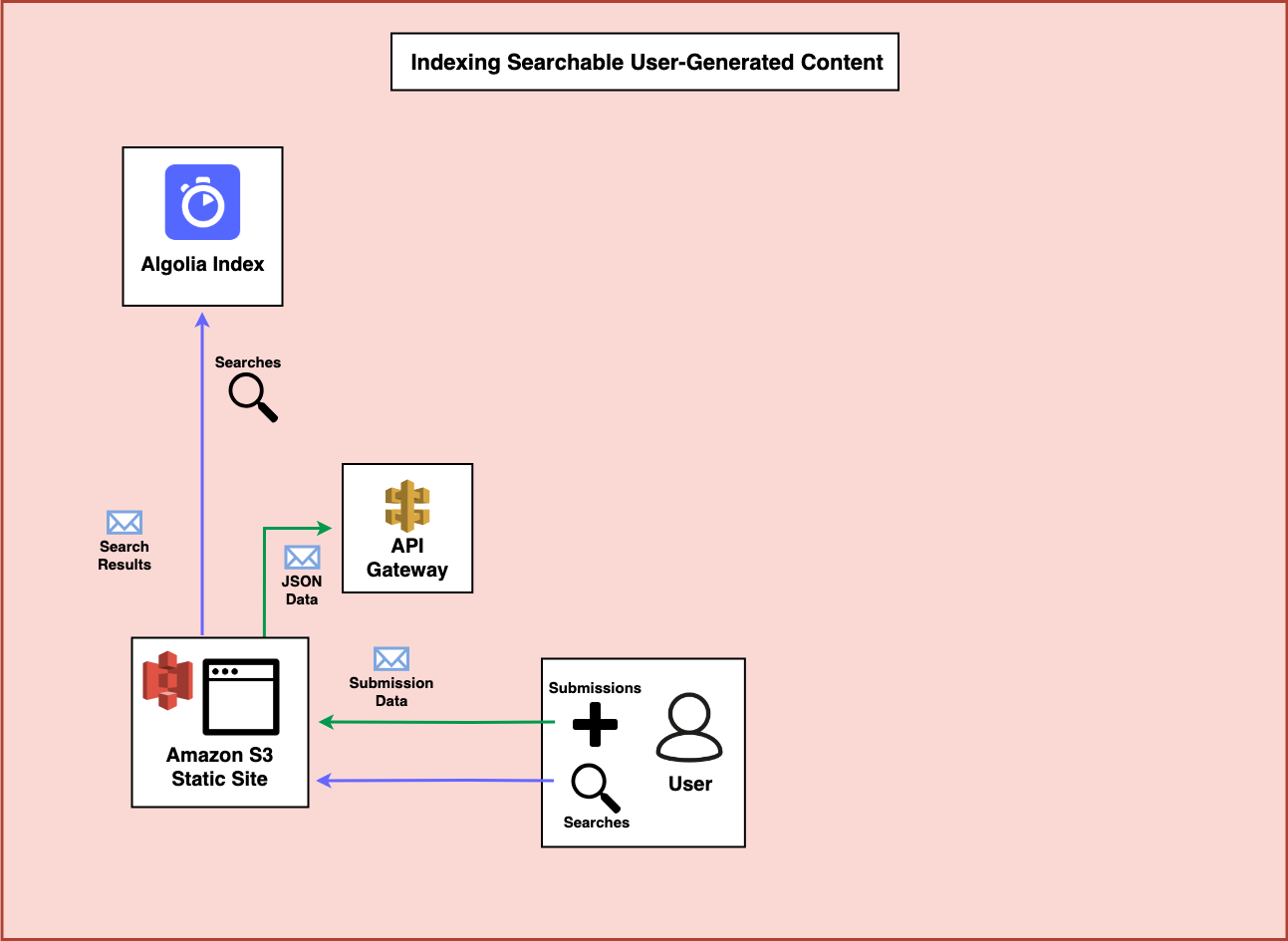
Step 4 - AWS Lambda with an IAM Role
When you use the Serverless Framework to create an API Gateway endpoint you’ll need a Lambda function behind that endpoint to process the JSON data that is sent in. This Lambda function will also need an IAM role which contains permissions to act on AWS Services it needs to interact with.
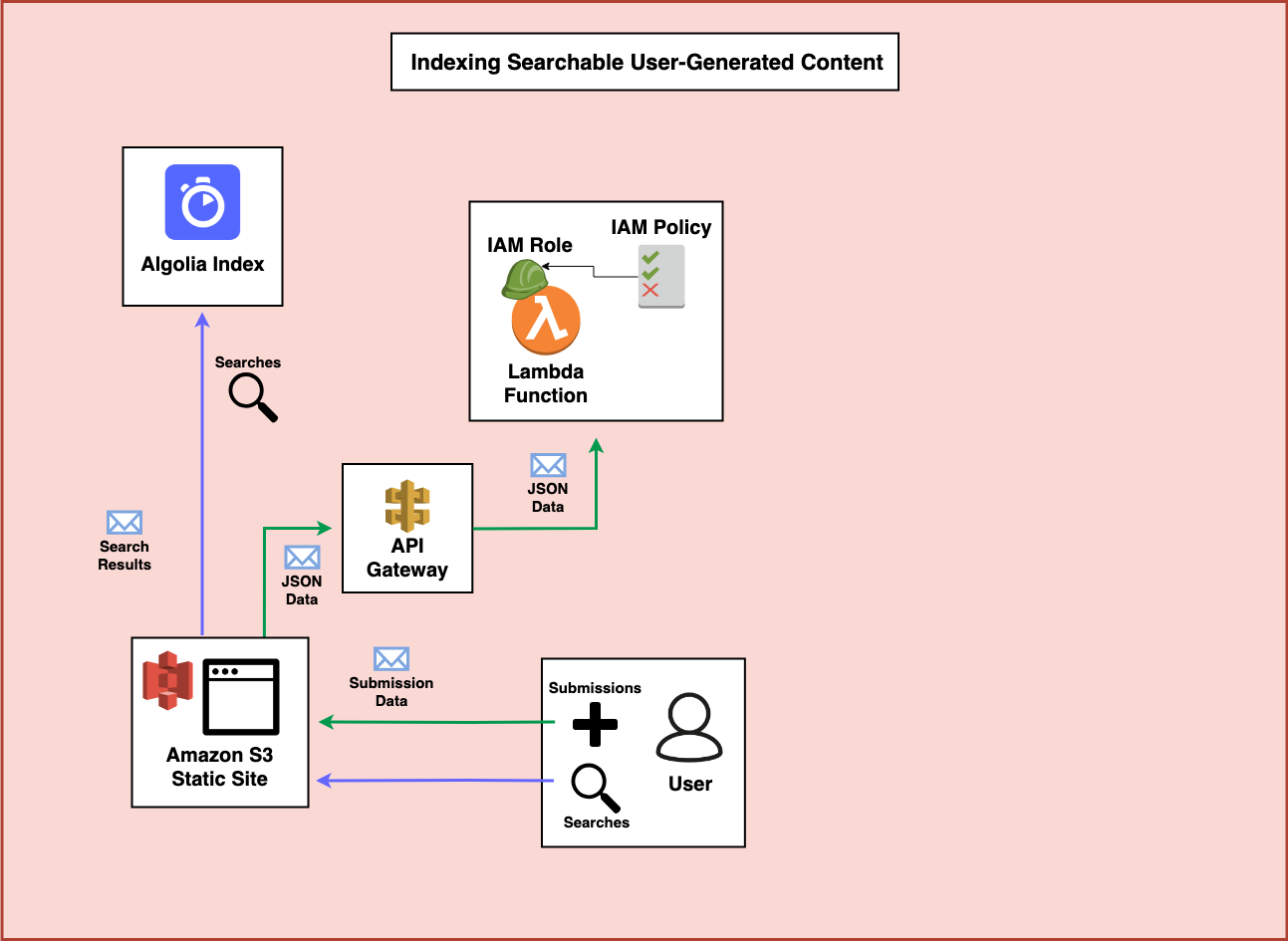
Step 5 - DynamoDB
I’m working under the assumption that you’ve decided that storing and updating transactional records in a low-latency high-throughput tool like DynamoDB is a priority for your application. If you’re not confident DynamoDB is a fit for you and are still deciding which database to use in your serverless applications, I suggest reviewing this post by Alex DeBrie which goes into significant detail on how to select one. But you also want to make your data easily searchable across many fields (something DynamoDB is not suited to). How could we accomplish this? One of the most practical ways is to write data both to DynamoDB and to a tool like Algolia or ElasticSearch. Let’s take a look at how this might happen.
With the permissions from the IAM role, the Lambda function can process the incoming submission, verify it’s quality (potentially via reCAPTCHA), and then send the data to DynamoDB.
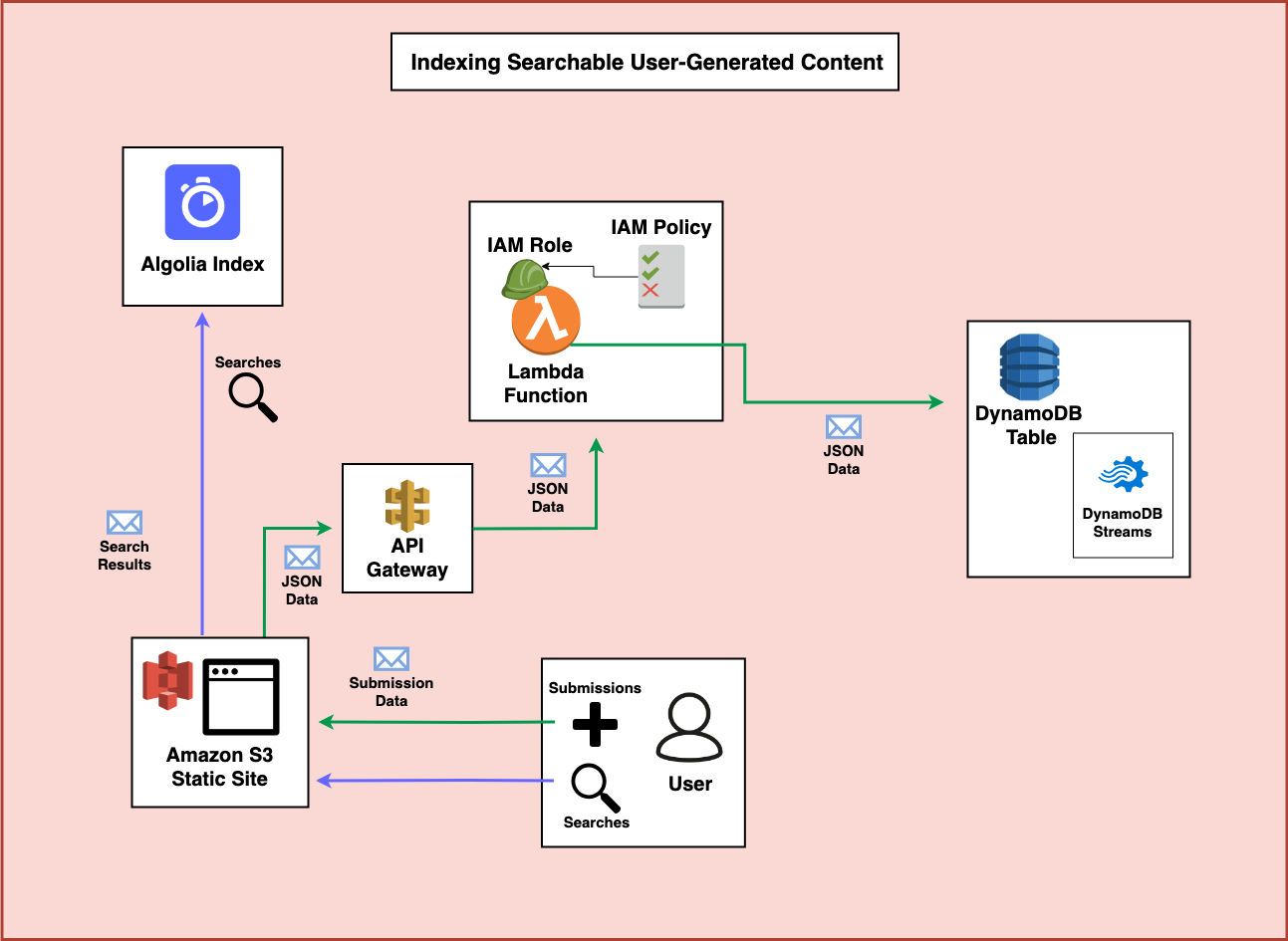
Step 6 - Indexing in Algolia
In addition to sending the data to DynamoDB, the Lambda Function can also index information in Algolia to make it immediately available for search. It can do this by creating an Algolia client from API credentials securely stored and encrypted in SSM Parameter Store.
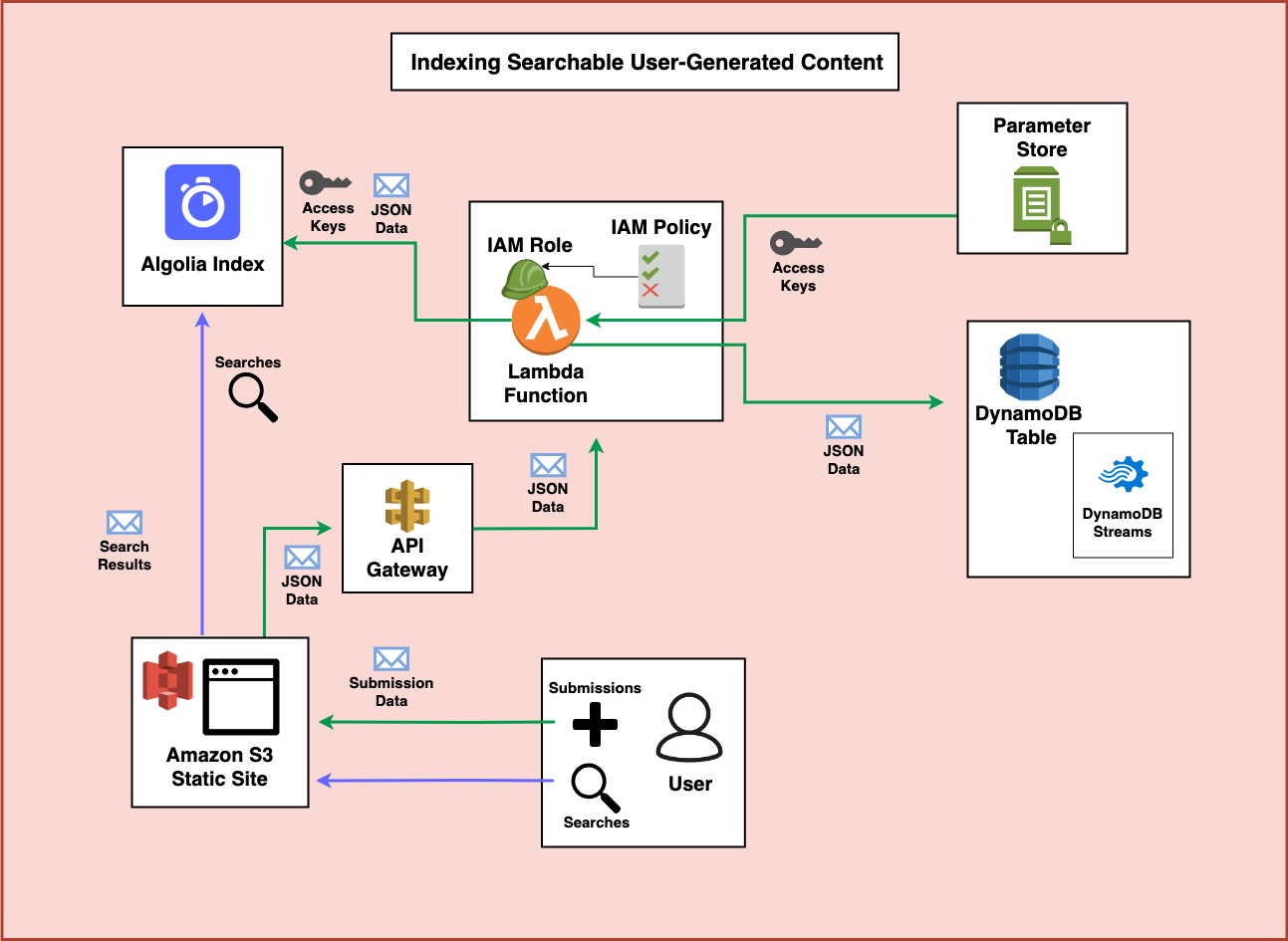
Step 7 - Adding Downstream Jobs
DynamoDB also has a feature called DynamoDB Streams. Whenever DynamoDB tables are updated you can use the feature to trigger additional processing using AWS Lambda. So, if you need to take further action on the new data, or if later on another process updates the items in the DynamoDB table, you can also create functions to keep the Algolia index fresh.
Conclusions
When building an application with serverless technologies one of the most common initial questions I see is “What database technology should I use?”. While there are many possible correct answers to this question, sometimes the answer is not a one-size-fits-all approach. In other words, you may actually want to use multiple tools to suit the needs of your application as shown in this architecture.
Is there another architecture you’d like help with? Leave a comment below or get in touch